目录
写在前面
- 其实是前段时间写的程序了,但是一直没有在博客上记录下来,现在终于想起来了就写一下。
- 本文主要是记录一下这个程序的开发过程。
纯纯流水账没啥好看的捏
项目简介




-
本项目是一个用于下载西安电子科技大学录直播平台课程视频的工具。
-
只需输入任意一节课的
liveId,即可自动下载单节课/单集(半节课)/该课程的所有视频。liveId是课程直播的唯一标识,可以在课程直播页面的 URL 中找到。如:http://newesxidian.chaoxing.com/live/viewNewCourseLive1?liveId=12345678中的12345678。 -
同时会保存选择下载的范围内所有视频的 m3u8 链接到对应的
csv表格中,方便使用其他方式下载。 -
下载时会自动检查之前是否下载过同一节课,如果已经下载则会跳过。所以可以在一学期中的多个时候随时下载新增的录播视频。
-
下载的视频按照课程和时间整理,下载多个课程的视频也不会冲突。
-
文件夹和
csv表格命名规则:年份-课程号-课程名。 -
课程视频命名规则:课程号-课程名-年月日-周次-节号-视频来源。、
项目地址
- lsy223622/XDUClassVideoDownloader
- 项目介绍、使用方法、源代码和打包程序都在上面链接里,这里就不重复了哦~
开发过程
开始是怎么想到做这个的呢?
- 期末复习的时候,发现学校的录直播平台上有很多课程的录播视频,但是没有下载的按钮,只能在线观看。
- 但是在线观看的时候经常会卡顿,而且有时候需要反复观看,所以想着能不能下载下来看。
- 开始想到了 IDM 的视频下载功能,但是体验真不算好:
- 首先需要打开每个视频的播放页面,等待漫长的加载时间,IDM 才能检测到视频。
- 然后要在每个视频的角落里一个一个点用 IDM 下载,下完所有视频得累死。
- 而且下载的视频文件名也是随机的一串数字,需要手动整理。
- 碰巧看到群友提到录直播平台有能获取一节课所有视频链接的接口,于是就想着能不能写一个脚本来批量下载视频。
开干!(超级流水账环节!)
-
根据群友提供的链接,使用
Curl尝试了一下,确实能得到所有视频链接。- 这个链接能使用一节课的
liveId获取到这门课所有视频的信息,包括课程号、课程名称、教师名称、上课教室、上课时间、liveId等信息,群友提供的链接参数非常复杂,我筛选测试之后发现只保留以下参数就能工作:- 接口链接:
http://newesxidian.chaoxing.com/live/listSignleCourse(Single拼成了Signle,程序员扣大分) - URL 参数:
liveId=12345678(随便一节课就行,不一定要第一节课) - User-Agent:
Mozilla/5.0(UA 感觉是黑名单制度,curl不定义 UA 能正常工作,但 Python 的requests就不行,所以我就随便填了这个,能用就行) - Cookie:
UID=2(非空就行,随便给个数字,这鉴权太草率了吧)
- 接口链接:
- 这个链接能使用一节课的
liveId获取到这节课的录播查看页面链接,返回链接的 URL 参数是一段 URL 编码后的 Json,解码后能得到三个视频的 m3u8 链接,包括pptVideoteacherTrackstudentFull,分别是投影仪画面、教师画面(自动追踪)和教室学生画面(黑板左上角的摄像头对着整个教室拍,但这个视频下载下来大多是破碎的,也没啥用,网页上播放的时候是隐藏的)。同样是筛选清理之后的参数:- 接口链接:
http://newesxidian.chaoxing.com/live/getViewUrlHls - URL 参数:
liveId=12345678&status=2(status=2好像是需要的,但我忘记为什么了) - User-Agent:
Mozilla/5.0(同上) - Cookie:
UID=2(同上)
- 接口链接:
- 这个链接能使用一节课的
-
然后我直接把这一堆请求、返回值、解析处理的逻辑发给 ChatGPT,让它实现获取一门课所有视频的 m3u8 链接和时间等信息并保存到一个
csv表格里的功能。多亏了 GPT-4o,给我提供了一段非常完美的 Python 代码。展开查看 ChatGPT 给出的代码(那时候请求参数还没清理)
import subprocess import json import csv import urllib.parse def get_initial_data(): curl_command = [ "curl", "http://newesxidian.chaoxing.com/live/listSignleCourse", "--compressed", "-X", "POST", "-H", "User-Agent: Mozilla/5.0 (Wayland; Linux x86_64; rv:120.1) Gecko/20100101 Firefox/120.1", "-H", "Accept: application/json, text/javascript, */*; q=0.01", "-H", "Accept-Language: en-US,en;q=0.7,ja;q=0.3", "-H", "Accept-Encoding: gzip, deflate", "-H", "Content-Type: application/x-www-form-urlencoded; charset=UTF-8", "-H", "X-Requested-With: XMLHttpRequest", "-H", "Origin: http://newesxidian.chaoxing.com", "-H", "DNT: 1", "-H", "Sec-GPC: 1", "-H", "Connection: keep-alive", "-H", "Referer: http://newesxidian.chaoxing.com/live/viewNewCourseLive1?isStudent=1", "-H", "Cookie: UID=9876", "--data-raw", "liveId=11740668" ] result = subprocess.run(curl_command, capture_output=True, text=True) return json.loads(result.stdout) def get_m3u8_links(live_id): curl_command = [ "curl", f"http://newesxidian.chaoxing.com/live/getViewUrlHls?liveId={live_id}&status=2&jie=&isStudent=", "--compressed", "-H", "User-Agent: Mozilla/5.0", "-H", "Accept: */*", "-H", "Accept-Language: en-US,en;q=0.7,ja;q=0.3", "-H", "Accept-Encoding: gzip, deflate", "-H", "X-Requested-With: XMLHttpRequest", "-H", "DNT: 1", "-H", "Sec-GPC: 1", "-H", "Connection: keep-alive", "-H", "Referer: http://newesxidian.chaoxing.com/live/viewNewCourseLive1?isStudent=1", "-H", "Cookie: UID=2" ] result = subprocess.run(curl_command, capture_output=True, text=True) response = result.stdout url_start = response.find('info=') if url_start == -1: raise ValueError("info parameter not found in the response") encoded_info = response[url_start + 5:] decoded_info = urllib.parse.unquote(encoded_info) info_json = json.loads(decoded_info) video_paths = info_json.get('videoPath', {}) ppt_video = video_paths.get('pptVideo', '') teacher_track = video_paths.get('teacherTrack', '') student_full = video_paths.get('studentFull', '') return ppt_video, teacher_track, student_full def main(): data = get_initial_data() rows = [] for entry in data: live_id = entry["id"] month = entry["startTime"]["month"] date = entry["startTime"]["date"] day = entry["startTime"]["day"] jie = entry["jie"] days = entry["days"] ppt_video, teacher_track, student_full = get_m3u8_links(live_id) row = [month, date, day, jie, days, ppt_video, teacher_track, student_full] rows.append(row) with open('m3u8.csv', mode='w', newline='') as file: writer = csv.writer(file) writer.writerow(['month', 'date', 'day', 'jie', 'days', 'pptVideo', 'teacherTrack', 'studentFull']) writer.writerows(rows) print("m3u8.csv 文件已创建并写入数据。") if __name__ == "__main__": main() -
我之前并没有写过 Python 程序,于是按照习惯让 ChatGPT 在 Python 中调用
Curl命令行。之后经群友提醒换成了 Python 的requests库,这样代码更简洁,无需调用外部程序。展开查看改用 requests 库的第一段请求代码
def get_initial_data(): url = "http://newesxidian.chaoxing.com/live/listSignleCourse" headers = { "User-Agent": "Mozilla/5.0 (Wayland; Linux x86_64; rv:120.1) Gecko/20100101 Firefox/120.1", "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Language": "en-US,en;q=0.7,ja;q=0.3", "Accept-Encoding": "gzip, deflate", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "X-Requested-With": "XMLHttpRequest", "Origin": "http://newesxidian.chaoxing.com", "DNT": "1", "Sec-GPC": "1", "Connection": "keep-alive", "Referer": "http://newesxidian.chaoxing.com/live/viewNewCourseLive1?isStudent=1", "Cookie": "UID=9876" } data = { "liveId": "11740668" } response = requests.post(url, headers=headers, data=data) response.raise_for_status() return response.json() -
程序一动不动地在那里默默干活肯定不行,我们也需要知道它有没有死,于是使用
tqdm加了一个进度条。展开查看使用 tqdm 的代码
for entry in tqdm(data, desc="Processing entries"): live_id = entry["id"] month = entry["startTime"]["month"] date = entry["startTime"]["date"] day = entry["startTime"]["day"] jie = entry["jie"] days = entry["days"] ppt_video, teacher_track, student_full = get_m3u8_links(live_id) row = [month, date, day, jie, days, ppt_video, teacher_track, student_full] rows.append(row) -
获取到 m3u8 链接之后,就可以让它调用下载程序下载视频了。这里我使用了 N_m3u8DL-RE,因为 m3u8 是一种索引文件,里面包含了视频的分段链接,
N_m3u8DL-RE可以自动下载并合并这些分段视频。展开查看使用 subprocess 调用 N_m3u8DL-RE 的代码
command = f'N_m3u8DL-RE.exe "{url}" --save-dir "m3u8" --save-name "{filename}"' subprocess.run(command, shell=True, check=True) -
为了让文件名信息丰富易于整理,按照“courseCodecourseNamex年x月x日第days周星期day第jie节-pptVideo/teacherTrack”的格式命名,星期几转换成更加符合习惯的汉字。
展开查看文件名命名代码
def day_to_chinese(day): days = ["日", "一", "二", "三", "四", "五", "六"] return days[day] for row in tqdm(rows, desc="Downloading videos"): month, date, day, jie, days, ppt_video, teacher_track, student_full = row day_chinese = day_to_chinese(day) if ppt_video: filename = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}节-pptVideo" download_m3u8(ppt_video, filename) if teacher_track: filename = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}节-teacherTrack" download_m3u8(teacher_track, filename) -
接口提供的信息没有年份,倒是有时间戳。如果是重修的话一门课就会上不止一次,为了可以收藏不同学年的同一节课,改成用时间戳转换得到年月日。
展开查看时间戳转换代码
start_time_unix = start_time / 1000 start_time_struct = time.gmtime(start_time_unix) month = start_time_struct.tm_mon date = start_time_struct.tm_mday -
判断是否存在已经下载的视频,存在就跳过下载。
展开查看更新后的代码
for row in tqdm(rows, desc="Downloading videos"): month, date, day, jie, days, ppt_video, teacher_track = row day_chinese = day_to_chinese(day) if ppt_video: filename = f"{course_code}{course_name}{year}年{month}月{date}日第{days}周星期{day_chinese}第{jie}节-pptVideo" filepath = os.path.join(save_dir, f"{filename}.ts") if os.path.exists(filepath): print(f"{filepath} 已存在,跳过下载。") else: download_m3u8(ppt_video, filename, save_dir) if teacher_track: filename = f"{course_code}{course_name}{year}年{month}月{date}日第{days}周星期{day_chinese}第{jie}节-teacherTrack" filepath = os.path.join(save_dir, f"{filename}.ts") if os.path.exists(filepath): print(f"{filepath} 已存在,跳过下载。") else: download_m3u8(teacher_track, filename, save_dir) -
感谢群友 chi(Waylandhater 提出的添加命令行使用方法和单个视频下载模式,并且十分贴心地发了 pull request,直接帮我搞定了。
展开查看添加命令行使用方法的代码
from argparse import ArgumentParser def main(liveid_from_cli=None, command=''): while True: if liveid_from_cli: input_live_id = liveid_from_cli liveid_from_cli = None else: input_live_id = input("请输入 liveId:") ...... def parse_arguments(): parser = ArgumentParser(description='用于下载西安电子科技大学录直播平台课程视频的工具') parser.add_argument('liveid', nargs='?', default=None, help='直播ID,不输入则采用交互式方式获取') parser.add_argument('-c', '--command', default='', help='自定义下载命令,使用 {url}, {save_dir}, {filename} 作为替换标记') args = parser.parse_args() return args if __name__ == "__main__": args = parse_arguments() main(liveid_from_cli=args.liveid, command=args.command)展开查看添加单个视频下载模式的代码
def main(liveid_from_cli=None, command='', single=False): while True: if liveid_from_cli: input_live_id = liveid_from_cli ...... for entry in tqdm(data, desc="Processing entries"): live_id = entry["id"] if single and str(live_id) != input_live_id: continue ...... parser.add_argument('-s', '--single', default=False, action='store_true', help='仅下载单集视频') ...... if __name__ == "__main__": args = parse_arguments() main(liveid_from_cli=args.liveid, command=args.command, single=args.single) -
群友说代码开头要加一行 shebang,我就加了一行 shebang。这 shebang 有啥用呢?我也不知道,但网上一搜说是在 Linux 上运行要用的,指定执行这个代码的程序路径。这行一加,看起来代码没啥变化,结果 Windows 上双击运行不起来了,按说是行注释吧,但是双击之后就是闪退。你们 Linux 真的是(指指点点)。
展开查看添加的 shebang
#!/usr/bin/env python3 -
那行吧,为了照顾 Linux 用户,这 shebang 就留着了。那 Windows 怎么办?我加了一个
bat文件,双击这个bat文件就能正常运行了。展开查看添加的 windows_run.bat 文件
@echo off python XDUClassVideoDownloader.py %* pause -
非常美丽脚本,这使我的运行环境旋转。我突然觉得每个用户在使用之前都照着 Readme 配一遍运行环境也太麻烦了,而且对小白用户来说也不友好,于是想到了把运行环境打包进去,这样用户只需要下载一个文件就能直接运行了。使用
pyinstaller打包之后就能得到一个XDUClassVideoDownloader.exe文件,不用配环境,双击就能运行了。展开查看打包命令
pip install pyinstaller python -m venv .venv .venv\Scripts\activate pip install requests tqdm pyinstaller --onefile --add-data "N_m3u8DL-RE.exe;." --add-data "ffmpeg.exe;." XDUClassVideoDownloader.py -
打包用的脚本最后需要添加一行,使它在执行结束之后不会自己关闭窗口,等按回车之后才会关闭。
展开查看等待输入的代码
input("按回车退出...") -
因为添加了 FFmpeg 这个庞然大物,打包之后的 exe 文件有好几十 MB,这可太大了。但是
N_m3u8DL-RE需要 FFmpeg,执行的时候会检测 FFmpeg 是否存在,不存在就不能正常用了。我还尝试把 FFmpeg 从 BtbN 编译的版本换成了 gyan.dev 编译的 essentials 版本,但是打包体积也就稍微小了一点,准确来说是从 58.5 MB 减小到了 43.9 MB,至少是个进步吧。 -
然后我又转念一想,这不对劲。我在
N_m3u8DL-RE的命令行参数里指定了使用二进制合并模式,也就是把下载的分段 ts 文件直接按照二进制编码拼接起来,理论上没有用到FFmpeg重新封装。于是我想出了一个神奇的糊弄方案:我用 c 写了个什么用都没有的程序,编译成exe文件,改名成FFmpeg.exe放到文件夹里。这样N_m3u8DL-RE就能检测到FFmpeg了,但是实际上并没有用到FFmpeg。这个程序的代码如下:展开查看什么用都没有的代码
int main() { return 0; }没用的代码你也看?😠
-
什么用都没有的
FFmpeg.exe编译出来是 15 KB,换上去N_m3u8DL-RE确实能正常运行。但我还是不满意。然后我突然想到可以用UPX压缩exe。结果是 8 KB。嗯,满意了。替换掉原来的FFmpeg.exe,打包之后的exe从 43.9 MB 减小到了 14.4 MB。展开查看使用 UPX 压缩的命令
upx --ultra-brute ffmpeg.exe -
N_m3u8DL-RE调用 FFmpeg 的时候如果 FFmpeg 不在Path中会找不到。但它也提供了一个命令行参数--ffmpeg-binary-path <PATH>来指定 FFmpeg 的路径。展开查看添加 FFmpeg 路径参数的代码
def resource_path(relative_path): base_path = getattr(sys, '_MEIPASS', os.path.dirname(os.path.abspath(__file__))) return os.path.join(base_path, relative_path) def download_m3u8(url, filename, save_dir, command=''): n_m3u8dl_re_path = resource_path('N_m3u8DL-RE.exe') ffmpeg_path = resource_path('ffmpeg.exe') if not command: command = f'./{n_m3u8dl_re_path} "{url}" --save-dir "{save_dir}" --save-name "{filename}" --check-segments-count False --binary-merge True --ffmpeg-binary-path "{ffmpeg_path}"' else: command = command.format(url=url, filename=filename, save_dir=save_dir, ffmpeg_path=ffmpeg_path) ...... -
这时候群友向我推荐了另一个 m3u8 下载器 vsd。它是用
Rust写的(我超,原!)。它的二进制合并模式不需要 FFmpeg。我试了一下,感觉体验不错,于是换成了这个。它的二进制文件比N_m3u8DL-RE大一点,但是我发现它没有经过压缩,于是用UPX压缩了一下,体积从 13.3 MB 减小到了 3.5 MB,打包体积 11.9 MB。展开查看使用 vsd 下载视频的代码
command = f'vsd-upx.exe save {url} -o {save_dir}\{filename} --retry-count 32 -t 16' -
换成
vsd之后,有一个功能也可以实现了,那就是下载视频之后自动合并上下半节课。录直播平台的视频是上下半节课分开的,但这两段视频在时间上是连续的,合并在一起更方便看,也方便整理。于是使用vsd的merge参数实现了这个功能。展开查看合并视频的函数(因为这个功能可以开关所以代码里到处都改了一点点,就不全部放上来了)
def merge_videos(files, output_file): if sys.platform.startswith('win32'): command = f'vsd-upx.exe merge -o {output_file} {" ".join(files)}' else: command = f'./vsd-upx merge -o {output_file} {" ".join(files)}' try: subprocess.run(command, shell=True, check=True) print(f"合并完成:{output_file}") for file in files: os.remove(file) except subprocess.CalledProcessError: print(f"合并 {output_file} 失败:\n{traceback.format_exc()}") -
添加合并视频功能涉及到了一大堆逻辑改动。
-
命名的时候,比如合并前文件名是
xxx第5节xxx和xxx第6节xxx,合并后的文件名就叫作xxx第5-6节xxx,文件名的其他部分保持不变。 -
合并的时候考虑到有些时候数据源会丢失几条视频数据,要正确处理视频链接或者视频文件不存在的错误,如果无法下载上下两个半节课或者其中一个半节课就跳过合并。
-
在判断视频是否存在的逻辑中加入检查合并了的文件,也就是:
- 如果上下半节合并的视频存在就跳过下载上下半节课
- 如果上下半节没有合并的两个视频都存在就尝试合并
- 如果只存在其中半节就尝试下载另外半节并且如果下载成功就尝试合并
-
合并成功后删除合并前的单个视频文件。
-
这个合并视频的功能作为可选项在交互式操作和命令行使用中都提供,默认合并。
-
选择不合并的命令行参数为
--no-merge。 -
不合并的话上面描述的逻辑都不生效,效果和之前的代码保持相同。
-
在交互模式中,如果选择只下载半节课视频,就不询问是否合并,也不执行合并功能。
展开查看修改后的 main 函数,这简直是一大坨,希望逻辑上没出错
def main(liveid=None, command='', single=0, merge=True): if not liveid: liveid = int(user_input_with_check( "请输入 liveId:", lambda liveid: liveid.isdigit() and len(liveid) <= 10 )) single = user_input_with_check( "是否仅下载单节课视频?输入 y 下载单节课,n 下载这门课所有视频,s 则仅下载单集(半节课)视频,直接回车默认单节课 (Y/n/s):", lambda single: single.lower() in ['', 'y', 'n', 's'] ).lower() if single in ['', 'y']: single = 1 elif single == 's': single = 2 else: single = 0 if single != 2: merge = user_input_with_check( "是否自动合并上下半节课视频?输入 y 合并,n 不合并,直接回车默认合并 (Y/n):", lambda merge: merge.lower() in ['', 'y', 'n'] ).lower() != 'n' else: if single > 2: single = 2 data = get_initial_data(liveid) if not data: print("没有找到数据,请检查 liveId 是否正确。") return if single: matching_entry = next( filter(lambda entry: entry["id"] == liveid, data)) if not matching_entry: raise ValueError("No matching entry found for the specified liveId") if single == 1: start_time = matching_entry["startTime"] data = list(filter( lambda entry: entry["startTime"]["date"] == start_time["date"] and entry["startTime"]["month"] == start_time["month"], data)) else: data = [matching_entry] first_entry = data[0] start_time = first_entry["startTime"]["time"] course_code = first_entry["courseCode"] course_name = first_entry["courseName"] start_time_unix = start_time / 1000 start_time_struct = time.gmtime(start_time_unix) year = start_time_struct.tm_year save_dir = f"{year}年{course_code}{course_name}" os.makedirs(save_dir, exist_ok=True) csv_filename = f"{year}年{course_code}{course_name}.csv" rows = [] for entry in tqdm(data, desc="获取视频链接"): live_id = entry["id"] days = entry["days"] day = entry["startTime"]["day"] jie = entry["jie"] start_time = entry["startTime"]["time"] start_time_unix = start_time / 1000 start_time_struct = time.gmtime(start_time_unix) month = start_time_struct.tm_mon date = start_time_struct.tm_mday ppt_video, teacher_track = get_m3u8_links(live_id) row = [month, date, day, jie, days, ppt_video, teacher_track] rows.append(row) with open(csv_filename, mode='w', newline='') as file: writer = csv.writer(file) writer.writerow(['month', 'date', 'day', 'jie', 'days', 'pptVideo', 'teacherTrack']) writer.writerows(rows) print(f"{csv_filename} 文件已创建并写入数据。") def process_rows(rows): for i in range(0, len(rows), 2): row1 = rows[i] month1, date1, day1, jie1, days1, ppt_video1, teacher_track1 = row1 day_chinese1 = day_to_chinese(day1) row2 = rows[i + 1] if i + 1 < len(rows) else None if row2: month2, date2, day2, jie2, days2, ppt_video2, teacher_track2 = row2 day_chinese2 = day_to_chinese(day2) ppt_video_files = [] if ppt_video1: filename1 = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}节-pptVideo.ts" filepath1 = os.path.join(save_dir, filename1) if not os.path.exists(filepath1): download_m3u8(ppt_video1, filename1, save_dir, command=command) ppt_video_files.append(filepath1) if ppt_video2: filename2 = f"{course_code}{course_name}{year}年{month2}月{date2}日第{days2}周星期{day_chinese2}第{jie2}节-pptVideo.ts" filepath2 = os.path.join(save_dir, filename2) if not os.path.exists(filepath2): download_m3u8(ppt_video2, filename2, save_dir, command=command) ppt_video_files.append(filepath2) if len(ppt_video_files) == 2 and merge: ppt_merged_filename = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}-{jie2}节-pptVideo.ts" ppt_merged_filepath = os.path.join(save_dir, ppt_merged_filename) merge_videos(ppt_video_files, ppt_merged_filepath) teacher_track_files = [] if teacher_track1: filename1 = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}节-teacherTrack.ts" filepath1 = os.path.join(save_dir, filename1) if not os.path.exists(filepath1): download_m3u8(teacher_track1, filename1, save_dir, command=command) teacher_track_files.append(filepath1) if teacher_track2: filename2 = f"{course_code}{course_name}{year}年{month2}月{date2}日第{days2}周星期{day_chinese2}第{jie2}节-teacherTrack.ts" filepath2 = os.path.join(save_dir, filename2) if not os.path.exists(filepath2): download_m3u8(teacher_track2, filename2, save_dir, command=command) teacher_track_files.append(filepath2) if len(teacher_track_files) == 2 and merge: teacher_merged_filename = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}-{jie2}节-teacherTrack.ts" teacher_merged_filepath = os.path.join(save_dir, teacher_merged_filename) merge_videos(teacher_track_files, teacher_merged_filepath) if single == 1: process_rows(rows[:2]) elif single == 2: row = rows[0] month, date, day, jie, days, ppt_video, teacher_track = row day_chinese = day_to_chinese(day) if ppt_video: filename = f"{course_code}{course_name}{year}年{month}月{date}日第{days}周星期{day_chinese}第{jie}节-pptVideo.ts" filepath = os.path.join(save_dir, filename) if not os.path.exists(filepath): download_m3u8(ppt_video, filename, save_dir, command=command) if teacher_track: filename = f"{course_code}{course_name}{year}年{month}月{date}日第{days}周星期{day_chinese}第{jie}节-teacherTrack.ts" filepath = os.path.join(save_dir, filename) if not os.path.exists(filepath): download_m3u8(teacher_track, filename, save_dir, command=command) else: process_rows(rows) print("所有视频下载和处理完成。")
-
-
几百行代码好长,我小小的脑子要看不过来了,于是我把代码拆分成了几个文件,分别是
XDUClassVideoDownloader.py、downloader.py、api.py、utils.py。这样代码结构更清晰,也方便维护。XDUClassVideoDownloader.py:主程序,用户交互和命令行参数解析
#!/usr/bin/env python3 import os import csv import time from argparse import ArgumentParser from tqdm import tqdm import traceback from utils import day_to_chinese, user_input_with_check, create_directory from downloader import download_m3u8, merge_videos from api import get_initial_data, get_m3u8_links def main(liveid=None, command='', single=0, merge=True): if liveid and not isinstance(liveid, int): liveid = int(liveid) elif not liveid: liveid = int(user_input_with_check( "请输入 liveId:", lambda liveid: liveid.isdigit() and len(liveid) <= 10 )) single = user_input_with_check( "是否仅下载单节课视频?输入 y 下载单节课,n 下载这门课所有视频,s 则仅下载单集(半节课)视频,直接回车默认单节课 (Y/n/s):", lambda single: single.lower() in ['', 'y', 'n', 's'] ).lower() if single in ['', 'y']: single = 1 elif single == 's': single = 2 else: single = 0 if single != 2: merge = user_input_with_check( "是否自动合并上下半节课视频?输入 y 合并,n 不合并,直接回车默认合并 (Y/n):", lambda merge: merge.lower() in ['', 'y', 'n'] ).lower() != 'n' else: if single > 2: single = 2 data = get_initial_data(liveid) if not data: print("没有找到数据,请检查 liveId 是否正确。") return if single: matching_entry = next( filter(lambda entry: entry["id"] == liveid, data)) if not matching_entry: raise ValueError("No matching entry found for the specified liveId") if single == 1: start_time = matching_entry["startTime"] data = list(filter( lambda entry: entry["startTime"]["date"] == start_time["date"] and entry["startTime"]["month"] == start_time["month"], data)) else: data = [matching_entry] first_entry = data[0] start_time = first_entry["startTime"]["time"] course_code = first_entry["courseCode"] course_name = first_entry["courseName"] start_time_unix = start_time / 1000 start_time_struct = time.gmtime(start_time_unix) year = start_time_struct.tm_year save_dir = f"{year}年{course_code}{course_name}" create_directory(save_dir) csv_filename = f"{year}年{course_code}{course_name}.csv" rows = [] for entry in tqdm(data, desc="获取视频链接"): live_id = entry["id"] days = entry["days"] day = entry["startTime"]["day"] jie = entry["jie"] start_time = entry["startTime"]["time"] start_time_unix = start_time / 1000 start_time_struct = time.gmtime(start_time_unix) month = start_time_struct.tm_mon date = start_time_struct.tm_mday ppt_video, teacher_track = get_m3u8_links(live_id) row = [month, date, day, jie, days, ppt_video, teacher_track] rows.append(row) with open(csv_filename, mode='w', newline='') as file: writer = csv.writer(file) writer.writerow(['month', 'date', 'day', 'jie', 'days', 'pptVideo', 'teacherTrack']) writer.writerows(rows) print(f"{csv_filename} 文件已创建并写入数据。") def process_rows(rows): for i in range(0, len(rows), 2): row1 = rows[i] month1, date1, day1, jie1, days1, ppt_video1, teacher_track1 = row1 day_chinese1 = day_to_chinese(day1) row2 = rows[i + 1] if i + 1 < len(rows) else None if row2: month2, date2, day2, jie2, days2, ppt_video2, teacher_track2 = row2 day_chinese2 = day_to_chinese(day2) ppt_video_files = [] if ppt_video1: filename1 = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}节-pptVideo.ts" filepath1 = os.path.join(save_dir, filename1) if not os.path.exists(filepath1): download_m3u8(ppt_video1, filename1, save_dir, command=command) ppt_video_files.append(filepath1) if ppt_video2: filename2 = f"{course_code}{course_name}{year}年{month2}月{date2}日第{days2}周星期{day_chinese2}第{jie2}节-pptVideo.ts" filepath2 = os.path.join(save_dir, filename2) if not os.path.exists(filepath2): download_m3u8(ppt_video2, filename2, save_dir, command=command) ppt_video_files.append(filepath2) if len(ppt_video_files) == 2 and merge: ppt_merged_filename = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}-{jie2}节-pptVideo.ts" ppt_merged_filepath = os.path.join(save_dir, ppt_merged_filename) merge_videos(ppt_video_files, ppt_merged_filepath) teacher_track_files = [] if teacher_track1: filename1 = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}节-teacherTrack.ts" filepath1 = os.path.join(save_dir, filename1) if not os.path.exists(filepath1): download_m3u8(teacher_track1, filename1, save_dir, command=command) teacher_track_files.append(filepath1) if teacher_track2: filename2 = f"{course_code}{course_name}{year}年{month2}月{date2}日第{days2}周星期{day_chinese2}第{jie2}节-teacherTrack.ts" filepath2 = os.path.join(save_dir, filename2) if not os.path.exists(filepath2): download_m3u8(teacher_track2, filename2, save_dir, command=command) teacher_track_files.append(filepath2) if len(teacher_track_files) == 2 and merge: teacher_merged_filename = f"{course_code}{course_name}{year}年{month1}月{date1}日第{days1}周星期{day_chinese1}第{jie1}-{jie2}节-teacherTrack.ts" teacher_merged_filepath = os.path.join(save_dir, teacher_merged_filename) merge_videos(teacher_track_files, teacher_merged_filepath) if single == 1: process_rows(rows[:2]) elif single == 2: row = rows[0] month, date, day, jie, days, ppt_video, teacher_track = row day_chinese = day_to_chinese(day) if ppt_video: filename = f"{course_code}{course_name}{year}年{month}月{date}日第{days}周星期{day_chinese}第{jie}节-pptVideo.ts" filepath = os.path.join(save_dir, filename) if not os.path.exists(filepath): download_m3u8(ppt_video, filename, save_dir, command=command) if teacher_track: filename = f"{course_code}{course_name}{year}年{month}月{date}日第{days}周星期{day_chinese}第{jie}节-teacherTrack.ts" filepath = os.path.join(save_dir, filename) if not os.path.exists(filepath): download_m3u8(teacher_track, filename, save_dir, command=command) else: process_rows(rows) print("所有视频下载和处理完成。") def parse_arguments(): parser = ArgumentParser(description="用于下载西安电子科技大学录直播平台课程视频的工具") parser.add_argument('liveid', nargs='?', default=None, help="课程的 liveId,不输入则采用交互式方式获取") parser.add_argument('-c', '--command', default='', help="自定义下载命令,使用 {url}, {save_dir}, {filename} 作为替换标记") parser.add_argument('-s', '--single', action='count', default=0, help="仅下载单节课视频(-s:单节课视频,-ss:半节课视频)") parser.add_argument('--no-merge', action='store_false', help="不合并上下半节课视频") return parser.parse_args() if __name__ == "__main__": args = parse_arguments() try: main(liveid=args.liveid, command=args.command, single=args.single, merge=args.no_merge) except Exception as e: print(f"发生错误:{e}") print(traceback.format_exc())downloader.py:下载视频和合并视频的函数
#!/usr/bin/env python3 import subprocess import sys import os import traceback def download_m3u8(url, filename, save_dir, command=''): if not command: if sys.platform.startswith('win32'): command = f'vsd-upx.exe save {url} -o {save_dir}\{filename} --retry-count 32 -t 16' else: command = f'./vsd-upx save {url} -o {save_dir}/{filename} --retry-count 32 -t 16' else: command = command.format(url=url, filename=filename, save_dir=save_dir) MAX_ATTEMPTS = 2 for attempt in range(MAX_ATTEMPTS): try: subprocess.run(command, shell=True, check=True) break except subprocess.CalledProcessError: print(f"第 {attempt+1} 次下载 {filename} 出错:\n{traceback.format_exc()}\n重试中...") if attempt == MAX_ATTEMPTS - 1: print(f"下载 {filename} 失败。") def merge_videos(files, output_file): if sys.platform.startswith('win32'): command = f'vsd-upx.exe merge -o {output_file} {" ".join(files)}' else: command = f'./vsd-upx merge -o {output_file} {" ".join(files)}' try: subprocess.run(command, shell=True, check=True) print(f"合并完成:{output_file}") for file in files: os.remove(file) except subprocess.CalledProcessError: print(f"合并 {output_file} 失败:\n{traceback.format_exc()}")api.py:获取课程数据和 m3u8 链接的函数
#!/usr/bin/env python3 import requests import urllib.parse import json def get_initial_data(liveid): url = "http://newesxidian.chaoxing.com/live/listSignleCourse" headers = { "User-Agent": "Mozilla/5.0", "Cookie": "UID=2" } data = { "liveId": liveid } response = requests.post(url, headers=headers, data=data) response.raise_for_status() return response.json() def get_m3u8_links(live_id): url = f"http://newesxidian.chaoxing.com/live/getViewUrlHls?liveId={live_id}&status=2" headers = { "User-Agent": "Mozilla/5.0", "Cookie": "UID=2" } response = requests.get(url, headers=headers) response.raise_for_status() response_text = response.text url_start = response_text.find('info=') if url_start == -1: raise ValueError("info parameter not found in the response") encoded_info = response_text[url_start + 5:] decoded_info = urllib.parse.unquote(encoded_info) info_json = json.loads(decoded_info) video_paths = info_json.get('videoPath', {}) ppt_video = video_paths.get('pptVideo', '') teacher_track = video_paths.get('teacherTrack', '') return ppt_video, teacher_trackutils.py:一些工具函数,包含日期汉字转换、输入数据检查、目录创建
#!/usr/bin/env python3 import os def day_to_chinese(day): days = ["日", "一", "二", "三", "四", "五", "六"] return days[day] def user_input_with_check(prompt, check_func): while True: user_input = input(prompt) if check_func(user_input): return user_input else: print("输入错误,请重新输入:") def create_directory(directory): os.makedirs(directory, exist_ok=True) -
为了方便打包版本同步主分支代码,我新建了一个
windows-pack分支,时不时 rebase 一下。和主分支区别如下:XDUClassVideoDownloader.py末尾添加了等待输入,防止窗口自己关闭。downloader.py中的download_m3u8函数使用绝对路径而不是相对路径来调用vsd-upx.exe。utils.py中增加resource_path函数,用于获取二进制文件路径。
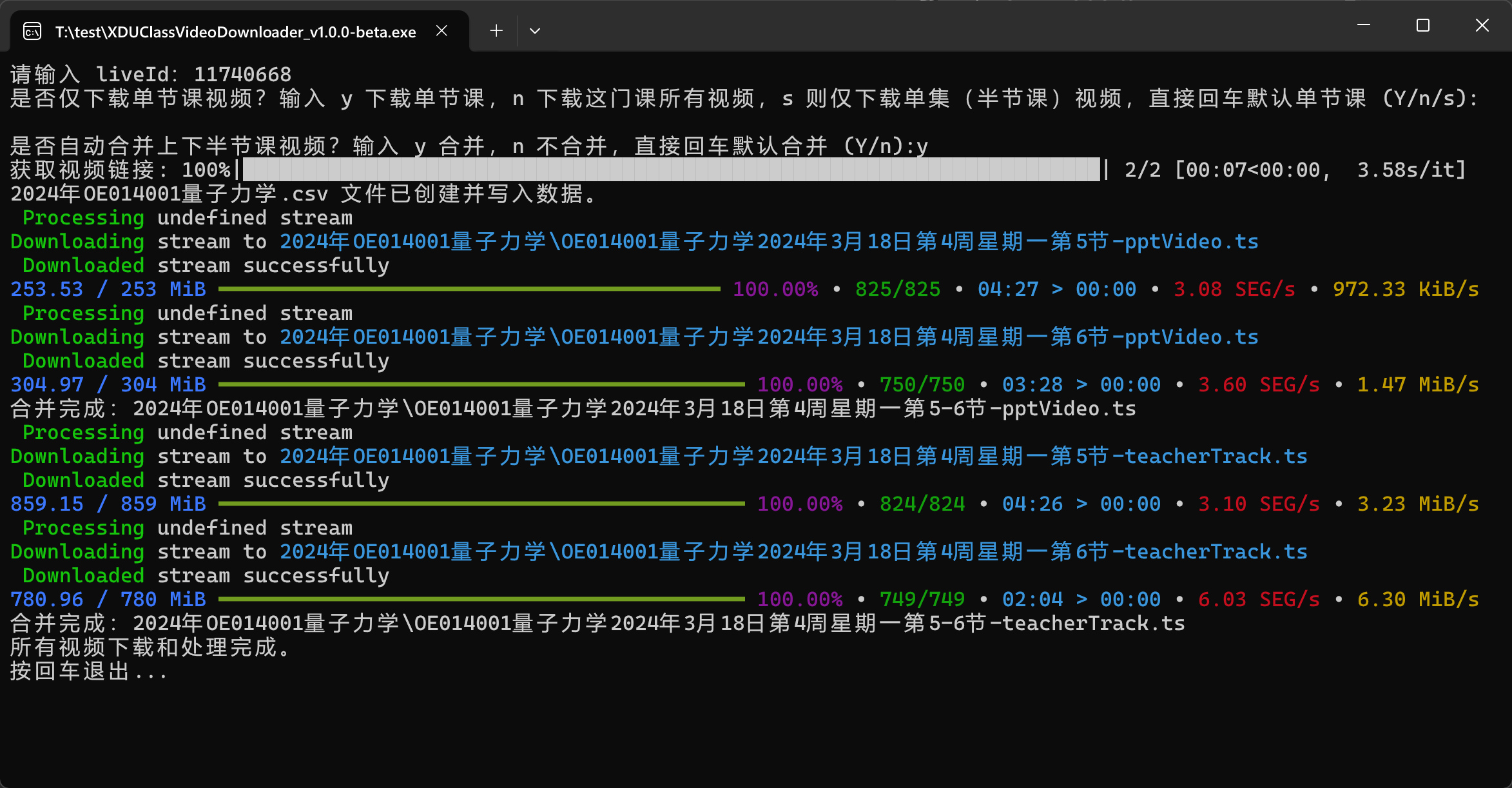
使用演示
- 打开最新 Release 页面,下载最新版本的
XDUClassVideoDownloader.exe文件。 - 双击运行
XDUClassVideoDownloader.exe,按照提示输入liveId,选择是否下载单节课视频,选择是否合并上下半节课视频。 - 等待下载完成,下载的视频在当前目录下的
年份+课程代码+课程名称文件夹中,下载用到的 m3u8 链接和对应的课程时间信息保存在同名csv表格中。
写在后面
- 最新的版本是
v1.0.0-beta,感觉基本上功能完善了,没啥需要改的了。 - 以后要是想到什么新功能再加吧,不过现在这个版本已经够用了。
- 大家要是有什么问题或者建议可以发 Issue 或者直接 QQ 找我。
- 我第一次在 GitHub 上有一个这么多 Star 的项目,开心捏。😋
- 编了这么多话可真是辛苦我了呢,那就写到这里吧~
评论
status 是 0=未开始,1=直播,2=观看回放,昨天趁着舍友去上课不在宿舍,偷偷登陆他的账号验证的。 而且学长竟然是物理专业的?我一个计算机专业的代码水平竟然不如学长,非常汗颜
原来是这样,我当时都没仔细研究 我是光电院的,代码基本上都是 AI 写的我只负责使唤它(
Linux执行python脚本也可以不需要Shebang 还有怎么不提一下写了JAVA脚本的我?差评取关(恼
好像确实是说不一定要有 shebang,但是既然可能有用那就还是加着吧。 你的 java 版和我的 py 脚本有什么关系😋要不把我后面的更新内容也同步一下